

The Power Of Big Data
June 5, 2015
What is Hadoop?
June 20, 2015
What is Big Data? – A beginner’s tutorial
In this blog post, we are going to see the following
- What is Big Data?
- Examples of Big Data
- What are the problems that come with Big Data?
- What Hadoop can offer in terms of solutions to the Big Data problems
- Hadoop vs. Traditional Solutions
What is Big Data?
If you ask me, tell me in one sentence what is Big Data?
I would say, Big Data is extremely huge volume of data.
To that answer the follow up question you can ask is – What is considered “huge” – 10 GB, 100 GB or 100 TB?
Well, there is no straight hard number that defines “huge” or Big Data. I know that is not the answer you are looking for. (I can see your disappointment :-)) . There are 2 reasons why there is no straight forward answer –
First, what is considered Big or huge today in terms is data size or volume need not be considered as Big a year from now. It is very much a moving target.
Second, it is all relative. What you and I consider to be “Big” may not be the case for companies like Google and Facebook.
Hence for the above 2 reasons, it is very hard to put a number to define big data volume. Let’s say if we are defining Big Data problem in terms of pure volume alone then in our opinion –
100 GB – Not a chance. We all have hard disk greater than 10 GB. Clearly not Big Data.
1 TB – Still no Because a well defined traditional database can handle 1 TB or even more without any issues.
100 TB – Likely. Some would claim 100 TB to be a Big Data problem and others might disagree. Again, its all relative.
1000 TB – Big Data problem.
Also volume of data is not the only factor to classify your data to be Big Data or not. So what other factors should be considered? Perfect segue to our next question.
Lets say we work at a startup and we recently launched a very successful email service where users can login to send and receive emails. Our email service is so good (better than gmail :-)), in 3 months we have 100,000 active users signed up and using our service. Hypothetically let’s say we are currently using a traditional database to store email messages and its attachments. Also, our current size of the database is 1 TB.
So, do we have a Big Data problem? The simple and straight answer is No. 1 TB or even more is a manageable size for a traditional database. The more important question is – at this growth rate, will we have a Big Data problem in the (near) future? To answer that we need to consider 3 factors.
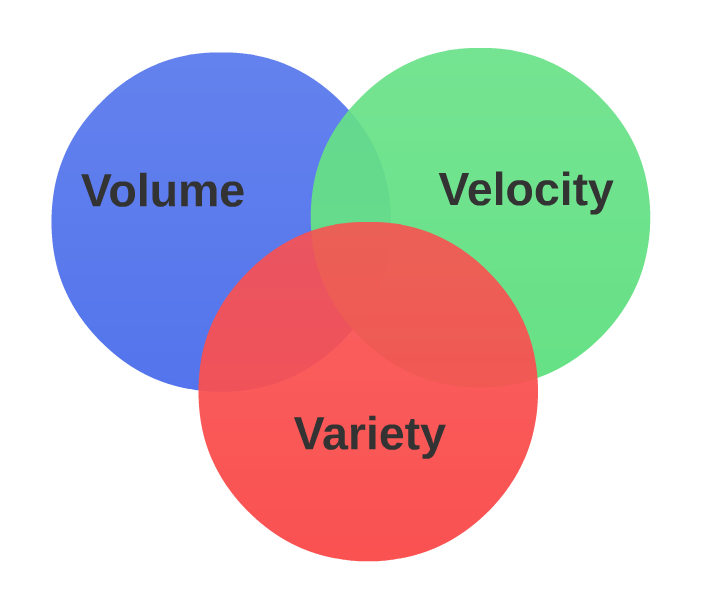
Volume
Obvious factor. In 3 months our startup has 100,000 active users and our volume is 1 TB. If we have positive growth at the same rate at the end of the year we will have 400,000 users and our volume will be 4 TB. End of year 2 with the same growth rate, we will have 8 TB. What if we doubled or tripled our user base every 3 months? So the bottom line is we should not just look at the volume when we think of Big Data we should also look at the rate in which our data grows. In other words, we should watch the velocity or speed of our data growth.
Velocity
This is an important factor. Velocity tells you how fast your data is growing. If your data volume stays at 1 TB for a year all you need is a good database but if the growth rate is 1 TB every week then you have to think about a scalable solution.
Most of the time Volume and Velocity is all you need to decide whether you have a Big Data problem or not.
Variety
Variety adds one more dimension to your analysis. Our data in traditional databases are highly structured i.e. rows and columns. But take for instance our hypothetical startup mail service, it receives data in various formats – text for mail messages, images and videos as attachments. When you have data coming in to your system in different formats and you have to process or analyze the data in different formats traditional database systems are sure to fail and when combined with high volume and velocity you for sure have a Big Data problem.
This happen to Big Data consultants all the time; they will be called in by clients with data storage or performance issues and hope that a Big data Solution like Hadoop is going to solve their problem and most of the time their answers will fail in the volume and velocity tests..
Their volume will be in the higher gigabytes and low Terabytes and their data growth is relatively low for the past 6 months and in the foreseeable future. Hence their volume does not qualify as big data and also the data growth is low and it fails the velocity test as well. What the client needs is to optimize the existing process and not a sophisticated Big Data solution.
Now you know what is Big Data and given a scenario if someone comes up to you and ask whether their data problems can be solved by Big Data solutions you know what are the factors that is – volume, velocity and variety that needs to be considered to make a sound decision.
So when we say Big Data we are potentially talking about 100s to 1000s of Terabytes.. if you are new to the Big Data space you are probably wondering is there really a use case? The answer is absolutely yes across all domains – science, government or private sector.
Examples of Big Data
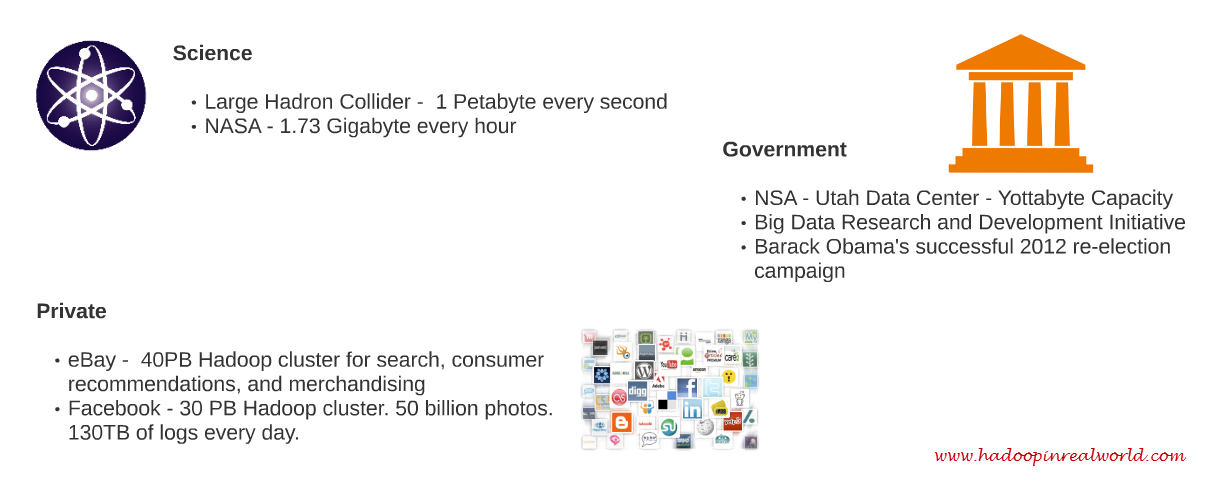
Lets talk about science first. The large Hadron Collider at CERN produce about 1 Petabyte of data every second, mostly sensor data. Their volume is so huge they don’t even retain or store all the data they produce. Source
NASA gathers about 1.73 Gigabytes of data every hour about weather, geo location data etc. Source
Lets talk about the government.. NSA is known for its controversial data collection programs and guess how much NSA’s data center at Utah can house in terms of volume? —- A Yottabyte of data that is, 1 Trillion Terabytes of data, pretty massive isn’t it? Source
In March of 2012 Obama’s administration announced to spend $200 million dollars in Big Data initiatives. Source
Even though we can not technically classify the next one under government, it’s an interesting use case so we included it anyway. Obama’s 2nd term election campaign used big data analytics which gave them a competitive edge to win the election. Source
Next let’s look at the private sector. With the advent of social media like Facebook, Twitter, LinkedIn etc. there is no scarcity of data. eBay is known to have at 30 PB cluster and Facebook 30 PB. The numbers are probably much much more now since the stats are old. Source
Not only in social media companies but also in retail space. It is most common in several major retail websites to capture click stream data. For example let’s say you shop at amazon.com, Amazon is not only capturing data when you click checkout, your every click on their website is tracked to bring a personalized shopping experience. When Amazon shows you recommendations, Big data analytics is at work behind the scenes.
You might be interested to know how Target could find out a women is pregnant using data analytics.
What are the problems that come with Big Data?
Now you should be convinced that Big Data exists, even if you did not believe it before.
So we have Big Data, so what?
Big data comes with big problems. Lets talk about few problems you may run in to when you deal with Big Data.
Since the datasets are huge, you need to find a way to store them as efficient as possible, I am not just talking about efficiency just in terms of storage space but also efficiency in storing the dataset that is suitable for computation. Another problem when you deal with big dataset you should worry about about data loss due to corruption in data or due to hardware failure and you need have proper recovery strategies in place.
The main purpose of storing data is to analyze them and how much time does it take to analyze and provide a solution to a problem using your big data is a million dollar question. What’s good in storing the data when you can not analyze or process the data in reasonable time right? With big datasets computation with reasonable execution times is a challenge.
Finally, cost. You are going to need a lot of storage space. So the storage solution that you plan to use should be cost effective.
But what is the need for new Big Data solution like Hadoop? Why traditional database solutions like MySQL or Oracle is not a good solution to store and analyze big datasets?
You will encounter scalability issues with traditional RDBMS when you start moving up in data volume in terms of terabytes. You will be forced to denormalize and pre aggregate the data for faster query execution time. As the data gets bigger you will be forced to make changes to the process in terms of changes to the indexes, optimizing queries etc.
If you worked with databases before, assuming your database is running in with enough hardware resources and when you see a performance issue still you will have to make some changes to the query itself or the way in which the data that you are accessing is stored and there is not working around it. You can not add more hardware resources or more computer nodes and distribute the problem to bring the computation times down. Meaning to say a database is not horizontally scalable.
The second problem with databases is that databases are designed to process structured data. Imagine when you have records that does not conform to a table like structure or each record in your dataset differs in the number of columns and there is no uniformity in the column lengths and types between rows. In this case database is not a good choice and when your data does not have a proper structure a database will struggle to store and process the data. Further more a database is not a good choice when you have a variety of data that is data in several formats like text, images etc.
Other challenge is cost. A good enterprise grade database solution can be quite expensive for relative low volume of data. When you add the hardware costs and the platinum grade storage costs it quickly adds up to the quite expensive.
So what is the solution? A good solution should –
- Of course, handle huge volume of data
- Efficient Storage – Ability to store data efficiently
- Recovery from Data loss – Data loss is unavoidable so the proposed solution should implement good recovery solution in place.
- The solution should horizontally scale as your data grows
- It should be Cost effective
- Minimize the learning curve – Easy for programmers & data analysts to work with the system.
That is exactly what Hadoop offers !!!
Apache Hadoop is an open-source software framework for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware.
Hadoop can handle huge volume of data, it can store data efficiently both in terms of storage and computation, it has good recovery solution for data loss and above all it can horizontally scale, so as your data gets bigger you add more nodes and Hadoop takes care of the rest. That simple.
Above all, Hadoop is cost effective – meaning we don’t need any specialized hardware to run Hadoop and hence great for even startups. Finally easy to learn and implement.
Hadoop vs. Traditional Solutions

High Performance or Grid Computing
Distributed computation is not a new concept. Traditional distributed solutions like Grid computing are essentially many nodes operating on data parallely and hence does faster computation. But there are 2 challenges with that though.
- Grid or High performance computating is good for compute intensive tasks with relatively low volume of data but does not perform well when the volume of data is huge..
- Grid computing requires a good experince with low level programming to implement and hence not suitable for mainstream..
RDBMS
What about Hadoop vs. RDBMS? Is Hadoop a replacement for Database? The straight answer is – no. There are things Hadoop is good at and there are things that database is good at.
RDBMS works exceptionally well with volume in the low terabytes where as with Hadoop the volume we speak is in terms of Petabytes.
Hadoop can work with Dynamic schema and can support files with many different formats where as the database schema is very strict and not so flexible and can not handle multiple formats
Database solutions can scale vertically meaning you can add more resources to the existing solution but will not horizontally scaling that is you can not bring down the execution time of a query by simply adding more computers.
Finally the cost, database solutions can get expensive very quick when you increase the volume of data you are trying to process. Where as Hadoop offers a cost effective solution. Hadoop infrastructure is made up of commodity computers meaning there is no need to special hardware. Commodity computers does not mean cheap computers it is still enterprise grade hardware but relative inexpensive as opposed specialize equipment.
Hadoop is a batch processing system. It is not as interactive as a database. You can not expect millisecond response times with Hadoop as you would expect in a database.
With Hadoop you write the file or dataset once and operate or analyze the data multiple times whereas with the database you can read and write multiple times.
But these gaps between Hadoop and RDBMS are closing in. Hadoop offers a cost effect solution to the big data problems but Hadoop is not the only solution that is available in the market now. NoSQL databases like HBase, Cassandra brings a great deal of value in analyzing huge volume of data and is a great alternative for RDBMS.
Conclusion
At this day and age, one thing is a fact – there is no shortage of information. That does not mean to say that a decade ago there was very less data. Few years ago, the data we collected but was not analyzed and were simply ignored due to the lack of framework or technology to analyze them at scale. Quite honestly ignoring data is not an option any more and it is important for businesses and organizations to analyze the data to to get realistic and useful predictions about their business and about their customers. With a great technology like Hadoop analyzing huge datasets has never been this easy and cost effective.
At this point you should have a good enough idea of what is classified Big Data and what are the challenges with it. We will move on to learn more about what is Hadoop and how it proposes a solution to store and analyze big datasets.


1 Comment
[…] https://www.bigdatainrealworld.com/what-is-big-data/ […]