
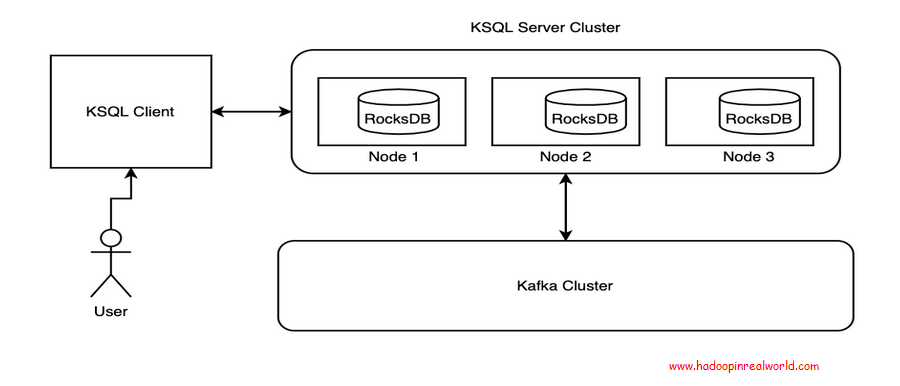
Building Stream Processing Applications using KSQL
June 1, 2020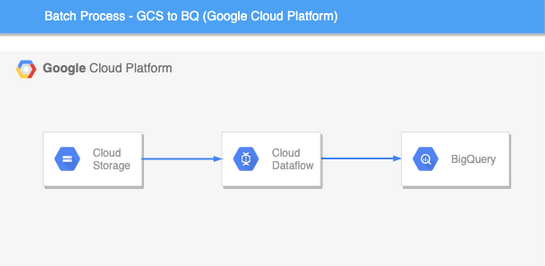
Batch Processing with Google Cloud DataFlow and Apache Beam
June 29, 2020NiFi is an open source data flow framework. It is highly automated for flow of data between systems. It works as a data transporter between data producer and data consumer. Producer means the system that generates data and consumer means the other system that consumes data. NiFi ensures to solve high complexity, scalability, maintainability and other major challenges of a Big Data pipeline.
NiFi is used extensively in Energy and Utilities, Financial Services, Telecommunication , Healthcare and Life Sciences, Retail Supply Chain, Manufacturing and many others.
Commonly used sources are data repositories, flat files, XML, JSON, SFTP location, web servers, HDFS and many others.
Destinations can be S3, NAS, HDFS, SFTP, Web Servers, RDBMS, Kafka etc.,
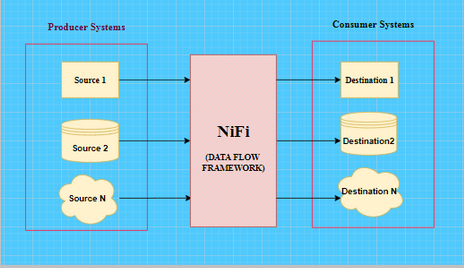
Why NiFi?
Primary uses of NiFi include data ingestion. In any Big Data projects, the biggest challenge is to bring different types of data from different sources into a centralized data lake. NiFi is capable of ingesting any kind of data from any source to any destination. NiFi comes with 280+ in built processors which are capable enough to transport data between systems.
Interested in getting in to Big Data? check out our Hadoop Developer In Real World course for interesting use case and real world projects just like what you are reading.
NiFi is an easy to use tool which prefers configuration over coding.
However, NiFi is not limited to data ingestion only. NiFi can also perform data provenance, data cleaning, schema evolution, data aggregation, transformation, scheduling jobs and many others. We will discuss these in more detail in some other blog very soon with a real world data flow pipeline.
Hence, we can say NiFi is a highly automated framework used for gathering, transporting, maintaining and aggregating data of various types from various sources to destination in a data flow pipeline.
A sample NiFi DataFlow pipeline would look like something below
Seems too complex right. This is the beauty of NiFi: we can build complex pipelines just with the help of some basic configuration. So, always remember NiFi ensures configuration over coding.
Step by step instructions to build a data pipeline in NiFi
Before we move ahead with NiFi Components. As a developer, to create a NiFi pipeline we need to configure or build certain processors and group them into a processor group and connect each of these groups to create a NiFi pipeline.
Let us understand these components using a real time pipeline.
Suppose we have some streaming incoming flat files in the source directory. Now, I will design and configure a pipeline to check these files and understand their name,type and other properties. This procedure is known as listing. After listing the files we will ingest them to a target directory.
We will create a processor group “List – Fetch” by selecting and dragging the processor group icon from the top-right toolbar and naming it.

Now, double click on the processor group to enter “List-Fetch” and drag the processor icon to create a processor. A pop will open, search for the required processor and add.
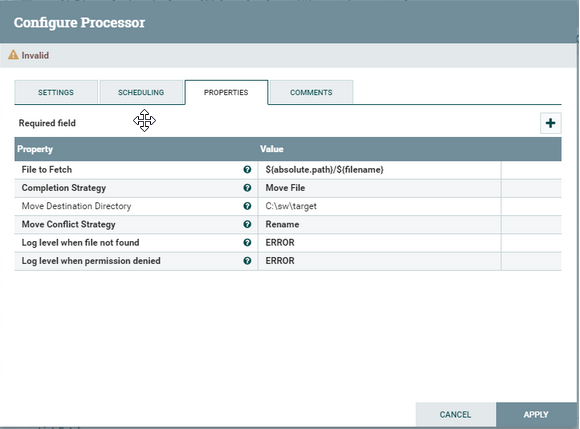
The processor is added but with some warning ⚠ as it’s just not configured . Right click and goto configure. Here, we can add/update the scheduling , setting, properties and any comments for the processor. As of now, we will update the source path for our processor in Properties tab. Each of the field marked in bold are mandatory and each field have a question mark next to it, which explains its usage.

Similarly, add another processor “FetchFile”. Move the cursor on the ListFile processor and drag the arrow on ListFile to FetchFile. This will give you a pop up which informs that the relationship from ListFile to FetchFile is on Success execution of ListFile. Once the connection is established. Warnings from ListFile will be resolved now and List File is ready for Execution. This can be confirmed by a thick red square box on processor.

Similarly, open FetchFile to configure. In the settings select all the four options from “Automatically Terminate Relationships”. This ensures that the pipeline will exit once any of these relationships is found.

Next, on Properties tab leave File to fetch field as it is because it is coupled on success relationship with ListFile. Change Completion Strategy to Move File and input target directory accordingly. Choose the other options as per the use case. Apply and close.
Pipeline is ready with warnings. Let’s execute it.

If we want to execute a single processor, just right click and start. For complete pipeline in a processor group. Goto the processor group by clicking on the processor group name at the bottom left navigation bar. Then right click and start.

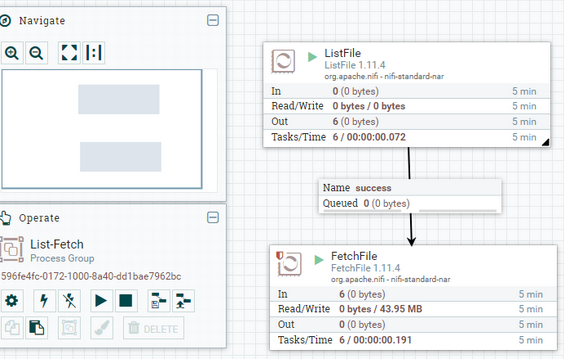
The green button indicates that the pipeline is in running state and red for stopped. Here, file moved from one processor to another through a Queue. If one of the processor completes and the successor gets stuck/stop/failed, the data processed will be stuck in Queue. Other details regarding execution history, summary, data provenance, Flow configuration history etc., can be accessed either by right click on processor/processor group or by clicking on three horizontal line button on top right.
This is a real world example of a building and deploying NiFi pipeline.
Like what you are reading? You would like our free live webinars too. Sign up and get notified when we host webinars =>
NiFi Components
Internally, NiFi pipeline consists of below components.
FlowFile
FlowFile represents the real abstraction that NiFi provides i.e., the structured or unstructured data that is processed. Structured data such as JSON or XML message and unstructured data such as images, videos, audios. FlowFile contains two parts – content and attribute.
Content keeps the actual information of the data flow which can be read by using GetFile, GetHTTP etc. while the attribute is in the key-value pair form and contains all the basic information about the content.
Processor
Processor acts as a building block of NiFi data flow. It performs various tasks such as create FlowFiles, read FlowFile contents, write FlowFile contents, route data, extract data, modify data and many more. As of today we have 280+ in built processors in NiFi. Do remember we can also build custom processors in NiFi as per our requirement.
Reporting Task
Reporting task is able to analyse and monitor the internal information of NiFi and then sends this information to the external resources.
Processor Group
It is a set of various processors and their connections that can be connected through its ports.
Queue
Queue as the name suggests it holds processed data from a processor after it’s processed.
FlowFile Prioritizer
It gives the facility to prioritize the data that means the data needed urgently is sent first by the user and remaining data is in the queue.
Flow Controller
Flow Controller acts as the brain of operations. It keeps the track of flow of data that means initialization of flow, creation of components in the flow, coordination between the components. It is responsible for managing the threads and allocations that all the processes use. Flow controller has two major components- Processors and Extensions.
NiFi Architecture
Consider a host/operating system (your pc), Install Java on top of it to initiate a java runtime environment (JVM). Consider a web server (such as localhost in case of local PC), this webserver primary work would be to host HTTP based command or control API.
Now let’s add a core operational engine to this framework named as flow controller. It acts as the brains of operation. Processors and Extensions are its major components.The Important point to consider here is Extensions operate and execute within the JVM (as explained above).
It is the Flow Controllers that provide threads for Extensions to run on and manage the schedule of when Extensions receives resources to execute.

Last but not the least let’s add three repositories FlowFile Repository, Content Repository and Provenance Repository.
FlowFile Repository
FlowFile Repository is a pluggable repository that keeps track of the state of active FlowFile.
Content Repository
Content Repository is a pluggable repository that stores the actual content of a given FlowFile. It stores data with a simple mechanism of storing content in a File System. More than one can also be specified to reduce contention on a single volume.
Provenance Repository
Provenance Repository is also a pluggable repository. It stores provenance data for a FlowFile in Indexed and searchable manner. provenance data refers to the details of the process and methodology by which the FlowFile content was produced. It acts as a lineage for the pipeline.
This is the overall design and architecture of NiFi. Please refer to the below diagram for better understanding and reference.
NiFi is also operational on clusters using Zookeeper server.
Apache NiFi Installation on your PC
Now, as we have gained some basic theoretical concepts on NiFi why not start with some hands-on. To do so, we need to have NiFi installed.
Please proceed along with me and complete the below steps irrespective of your OS:
Download
Create a directory of your choice.
Open a browser and navigate to the url https://nifi.apache.org/download.html

At the time of writing we had 1.11.4 as the latest stable release. Based on the latest release, go to “Binaries” section.
We are free to choose any of the available files however, I would recommend “.tar.gz “ for MAC/Linux and “.zip” for windows.
Install
While the download continues, please make sure you have java installed on your PC and JDK assigned to JAVA_HOME path.
Please do not move to the next step if java is not installed or not added to JAVA_HOME path in the environment variable.
Once the file mentioned in step 2 is downloaded, extract or unzip it in the directory created at step1.
Open the extracted directory and we will see the below files and directories

Open the bin directory above. The below structure appears.
Here, we can see OS based executables. So our next steps will be as per our operating system:
For MAC/Linux OS open a terminal and execute bin/nifi.sh run from installation directory or bin/nifi.sh start to run it in background.
To install NiFi as a service(only for mac/linux) execute bin/nifi.sh install from installation directory. This will install the default service name as nifi. For custom service name add another parameter to this command bin/nifi.sh install dataflow
For windows open cmd and navigate to bin directory for ex:
cd c:\sw\nifi-1.11.4-bin\nifi-1.11.4\bin
Then type run-nifi.bat and press enter
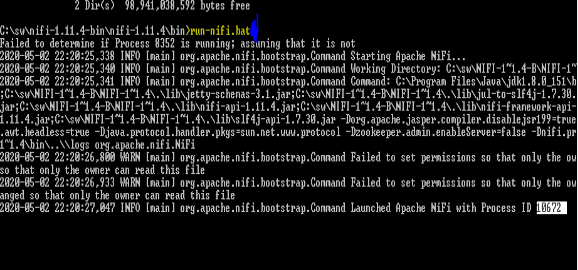
Go to logs directory and open nifi-app.log scroll down to the end of the page.
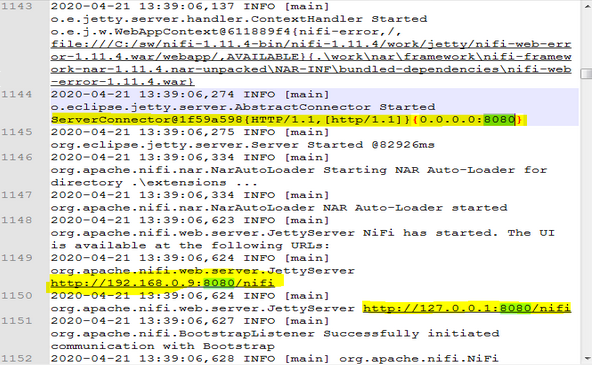
Here, in the log let us have a look at the below entry:
ServerConnector@1f59a598{HTTP/1.1,[http/1.1]}{0.0.0.0:8080}
Verify
By Default, NiFi is hosted on 8080 localhost port. Open browser and open localhost url at 8080 port http://localhost:8080/nifi/
We have our NiFi Home Page open.
This page confirms that our NiFi is up and running.
Like what you are reading? You would like our free live webinars too. Sign up and get notified when we host webinars =>

