
Big Data Interview Questions and Answers (Part 2)
March 11, 2019
Schema Registry & Schema Evolution in Kafka
January 11, 2020In this blog post we are going to show how to optimize your Spark job by partitioning the data correctly. To demonstrate this we are going to use the College Score Card public dataset, which has several key data points from colleges all around the United States. We will compute the average student fees by state with this dataset.
Do you like us to send you a 47 page Definitive guide on Spark join algorithms? ===>
Partition and Shuffle
Shuffle is an expensive operation whether you do it with plain old MapReduce programs or with Spark. Shuffle is he process of bringing Key Value pairs from different mappers (or tasks in Spark) by Key in to a single reducer (task in Spark). So all key value pairs of the same key will end up in one task (node). So we can loop through the key value pairs and do the needed aggregation.
Since production jobs usually involve a lot of tasks in Spark, the key value pairs movement between nodes during shuffle (from one task to another) will cause a significant bottleneck. In some cases Shuffle is not avoidable but in many instances you could avoid shuffle by structuring your data little differently. Avoiding shuffle will have an positive impact on performance.
Repartition the dataset in Parquet
Our dataset is currently in Parquet format. The dataset is already partitioned by state (column name – STABBR). We have set the number of partitions to 10. We have 50 states in the US, so by partitioning the dataset by state and by setting the number of partitions to 10, we will end up with 10 files. Partitioning the data by state helps us to store all the records for a given state in one file so the data for a state is not scattered across many files. A partition could have records for more than one state.
For eg. at run time if Spark decides all records for state NY should go to partition # 2, then all the records for NY from the dataset will be written to file # 2.
Let’s see how we can partition the data as explained above in Spark. Initially the dataset was in CSV format. We are going to convert the file format to Parquet and along with that we will use the repartition function to partition the data in to 10 partitions.
import org.apache.spark.sql.SaveMode
val colleges = spark
.read.format("csv")
.option("header", "true")
.load("/user/hirw/input/college")
val colleges_rp = colleges.repartition(partitionExprs = col("STABBR"), numPartitions = 10)
colleges_rp.write
.mode(SaveMode.Overwrite)
.format("parquet")
.option("inferSchema", false)
.save("/user/hirw/input/college_parquet")
Parquet is a much more efficient format as compared to CSV. You can compare the size of the CSV dataset and Parquet dataset to see the efficiency. CSV dataset is 147 MB in size and the same dataset in Parquet format is 33 MB in size. Parquet offers not just storage efficiency but also offers execution efficiency.
hirw@play2:~$ hadoop fs -du -s -h /user/hirw/input/college
147.3 M 441.8 M /user/hirw/input/college
hirw@play2:~$ hadoop fs -du -s -h /user/hirw/input/college_parquet
32.9 M 98.7 M /user/hirw/input/college_parquet
How does partition result in improving performance?
When the data is already partitioned on a column and when we perform aggregation operations on the partitioned column, the Spark task can simply read the file (partition), loop through all the records in the partition and perform the aggregation and it does not have to execute a shuffle because all the records needed to perform aggregation is inside the single partition. No shuffle would equal better performance.
Now that we have already partitioned our dataset on the state column and we would like to compute the average student fees by state – we are aggregating the data on the same column which is used for the partition. So this should not result in a shuffle. What do you think?
Let’s give it a try. Here is the code to compute average fees by state.
import org.apache.spark.sql.functions._
val colleges_parquet = spark.read
.format("parquet")
.option("header", true)
.option("inferSchema", false)
.load("/user/hirw/input/college_parquet")
val avg_student_fees_by_state = colleges_parquet.groupBy($"STABBR").agg(avg($"TUITIONFEE_OUT")).alias("avg_out_student_fees")
avg_student_fees_by_state.show
~~ Output ~~
+——+——————-+
|STABBR|avg(TUITIONFEE_OUT)|
+——+——————-+
| AZ| 13763.746268656716|
| SC| 16507.64|
| LA| 13080.415384615384|
| MN| 15321.97247706422|
| NJ| 17568.434210526317|
| DC| 23772.0|
| OR| 18013.036363636365|
| VA| 18098.120689655174|
| RI| 29762.5|
| KY| 16749.76388888889|
| WY| 8425.555555555555|
| NH| 21777.76|
| MI| 15696.561403508771|
| NV| 14703.55|
| WI| 16624.0641025641|
| ID| 14148.157894736842|
| CA| 16642.457386363636|
| CT| 22527.555555555555|
| NE| 14029.121951219513|
| MT| 11756.625|
+——+——————-+
only showing top 20 rows
Here is the visualization of the job which did the aggregation and computed the average and there you can see, two stages were involved and the below representation indicates a shuffle.
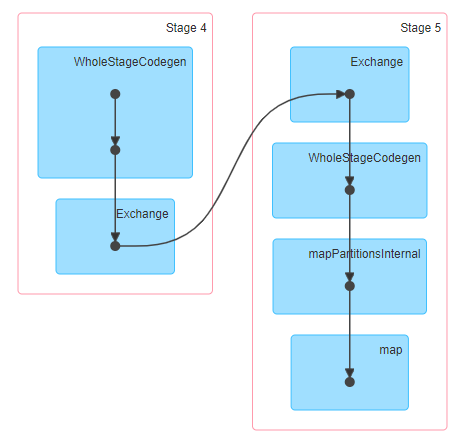
Why did Spark execute a shuffle, in-spite the data is already partitioned? The reason is simple, Spark does not know that the data was partitioned. There was no metadata associated with our dataset that Spark could read into to infer that the data is partitioned.
So to avoid shuffle we somehow need to let Spark know that the data is partitioned.
Bucket the data with Hive
When Spark loads the data that is behind a Hive table, it can infer how the table is structured by looking at the metadata of the table and by doing so will understand how the data is stored.
Since we are trying to aggregate the data by the state column, we can bucket the data by the state column. Doing so will result in very similar output as the repartition operation we did above.
Note: Hive support partitionBy operation as well and partitionBy on the state column will result in 50 separate files one per state.
In the below code, we organize our data in to 10 buckets and store it in a Hive table.
import org.apache.spark.sql.SaveMode
val colleges = spark
.read.format("csv")
.option("header", "true")
.load("/user/hirw/input/college")
colleges.write
.bucketBy(10, "STABBR")
.saveAsTable("colleges_hive")
When we repartition the dataset by setting the number of paritions to 10, we end up with 10 partitions or files. Now let’s see how many files we got when we bucket-ed the data by setting the number of buckets to 10.
hirw@play2:~$ hadoop fs -ls /user/hive/warehouse/colleges_hive
Found 31 items
We see a total of 31 items. Why? Shouldn’t we see just 10? The job which loaded the Hive table resulted in 3 tasks and each task created 10 buckets resulting in 3 *10= 30 files. The 31st file is the _SUCCESS file which is an empty file created by Spark indicating a successful load of data.
This means records for a single state can be spread across in 3 files because each task which process a portion of the dataset could have process the records for a given state. What would happen when we try to compute average fees by state? Will Spark be able to leverage the metadata from the Hive table and understand that the data is bucket-ed and avoid a Shuffle?
Let’s give it a try. Here is the code to compute average student fees by state against the Hive table
val colleges = spark.sql("SELECT * FROM colleges_hive")
val avg_student_fees_by_state = colleges.groupBy($"STABBR").agg(avg($"TUITIONFEE_OUT")).alias("avg_out_student_fees")
avg_student_fees_by_state.show
~~ Output ~~
+——+——————-+
|STABBR|avg(TUITIONFEE_OUT)|
+——+——————-+
| AZ| 13763.746268656716|
| SC| 16507.64|
| LA| 13080.415384615384|
| MN| 15321.97247706422|
| NJ| 17568.434210526317|
| DC| 23772.0|
| OR| 18013.036363636365|
| VA| 18098.120689655174|
| RI| 29762.5|
| KY| 16749.76388888889|
| WY| 8425.555555555555|
| NH| 21777.76|
| MI| 15696.561403508771|
| NV| 14703.55|
| WI| 16624.0641025641|
| ID| 14148.157894736842|
| CA| 16642.457386363636|
| CT| 22527.555555555555|
| NE| 14029.121951219513|
| MT| 11756.625|
+——+——————-+
only showing top 20 rows
We got the same output which is great. Let’s check the execution and see whether we Spark did a shuffle or not.
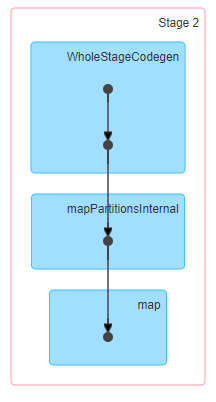
Above is the corresponding stage which computed the average student fees by state and we can see that Spark did not execute the shuffle. So this means even when the data for a given state was split possibly between the 3 files, Spark was able to infer that the table is a bucketed table by looking at the metadata of the table and will pass through the dataset to get an idea about the contents inside the buckets and was able to perform the execution by avoiding a shuffle.

